💡핵심 요약
1. 검색 패러다임의 대전환: 사용자는 이제 텍스트 창이 아닌 카메라(이미지)와 마이크(음성)로 세상을 탐색합니다. ‘멀티모달’이 검색의 새로운 표준입니다.
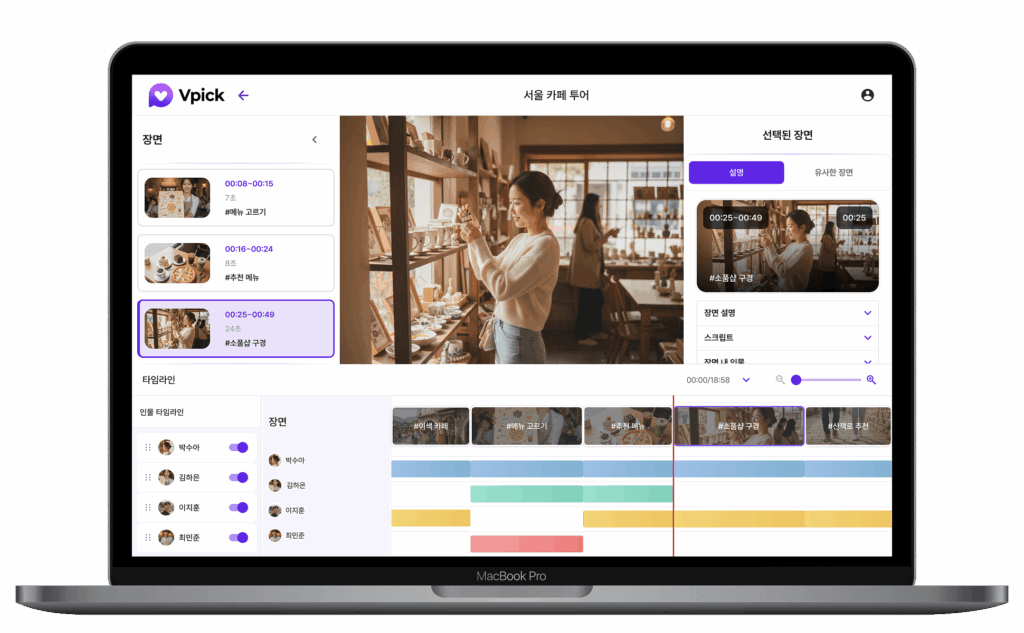
2. ‘장면(Scene)’이 곧 검색 결과: AI 검색은 영상 전체를 보여주지 않습니다. 질문에 대한 답이 있는 정확한 ‘장면’을 찾아 타임스탬프와 함께 제시합니다.
3. V-Pick의 역할: V-Pick은 긴 영상에서 검색 가치가 높은 핵심 장면을 AI로 ‘채굴(Mining)’하여, 멀티모달 검색 엔진이 이해할 수 있는 형태(숏폼, 메타데이터)로 가공합니다.
4. 마케터의 대응: 이제 키워드 반복이 아닌, ‘시각적 정보’와 ‘맥락’을 최적화하는 ‘장면 SEO’ 전략이 필수적입니다.
텍스트 검색의 시대가 저물고 있습니다
우리는 지난 20년 동안 구글과 네이버 검색창에 ‘텍스트’를 입력하는 데 익숙했습니다. 하지만 지금, 그 검색의 기본 전제가 무너지고 있습니다. Z세대의 40%는 검색 엔진 대신 틱톡(TikTok)이나 인스타그램을 사용하여 점심 메뉴를 찾습니다. 그들은 “강남역 맛집”이라고 치는 대신, 지도를 켜거나 음식 사진을 찍어 검색합니다.

이것이 바로 ‘멀티모달(Multi-modal) 검색’의 시작입니다. 텍스트뿐만 아니라 이미지, 오디오, 비디오 등 다양한 형태의 정보를 동시에 이해하고 검색하는 기술입니다. 이제 검색 엔진은 “이 신발 어디 브랜드야?”라는 텍스트 질문과 함께 업로드된 신발 사진을 보고, 정확한 브랜드와 구매 링크를 찾아줍니다.
검색 결과는 이제 ‘링크’가 아니라 ‘장면’입니다
멀티모달 시대의 가장 큰 변화는 검색 결과의 형태입니다. 과거에는 영상이 검색 결과에 뜨더라도, 사용자가 직접 영상을 클릭하고 타임바를 옮겨가며 원하는 내용을 찾아야 했습니다. 하지만 이제 AI는 다릅니다.
구글의 제미나이(Gemini)와 같은 최신 AI 모델은 영상의 맥락을 초 단위로 이해합니다. 사용자가 “아이폰 15 배터리 교체 방법 알려줘”라고 물으면, 10분짜리 리뷰 영상 전체를 던져주는 것이 아니라, 정확히 배터리를 분리하는 ‘그 장면(Scene)’으로 바로 이동시켜 줍니다.

이것이 ‘장면 검색(Scene Search)’입니다. 이제 당신의 영상이 검색에 노출되려면, 영상 전체의 제목뿐만 아니라 장면 하나하나가 검색 엔진에 읽힐 수 있어야 합니다. 영상 속에 어떤 사물이 등장하는지, 어떤 대화가 오가는지, 그 맥락이 데이터화되어 있어야 한다는 뜻입니다.
브이픽(Vpick): 숨겨진 ‘장면’을 찾아내는 AI 파트너
그렇다면 이미 만들어진 수많은 롱폼 영상들은 어떻게 해야 할까요? 일일이 돌려보며 중요한 장면을 자르고 태그를 달아야 할까요? 여기서 VPick의 가치가 증명됩니다.
VPick은 영상 속에서 검색 가치가 높은 ‘보석 같은 장면’을 찾아내는 ‘콘텐츠 마이닝(Content Mining)’ 솔루션입니다.

V-Pick의 AI는 영상의 음성(STT)과 시각 정보(Vision AI)를 분석하여, “이 구간이 ‘멀티모달 전략’에 대한 핵심 답변입니다”라고 식별해냅니다. 그리고 이를 즉시 숏폼으로 변환하거나, 검색 엔진이 좋아하는 메타데이터(타임스탬프, 요약, 태그)를 생성해줍니다.
결론: 찍는 것보다 중요한 것은 ‘발견되는 것’입니다
콘텐츠의 홍수 속에서 새로운 영상을 찍는 것만으로는 부족합니다. 이미 여러분이 가진 영상 자산(Asset) 속에 답이 있습니다.
2026년, 검색의 주도권은 ‘키워드를 잘 쓰는 사람’이 아니라 ‘장면을 잘 설계하는 사람’에게 넘어갈 것입니다. 텍스트의 종말을 두려워하지 마세요. V-Pick과 함께 당신의 영상을 가장 완벽한 ‘답변’으로 만드세요. 지금이 바로, 당신의 콘텐츠를 ‘채굴’할 시간입니다.